|
Okay so you’re bought into building with generative Ai (genAI) or you need some more data to build the case for the use of generative Ai in your products and you need to know how much external data you need to build something of value. This is the purpose of this document, to explore how much data you need to build a genAI product. PlanThe plan is crude. To limit the variability and time spent, I set out with some very clear parameters on how to test this. Firstly I decided the external data source should be something public, that already exists but could be repurposed into making sense as an actual product I could build for my clients. For that I decided on the instruction manual for a General Electric Oven. The oven manual is around 60 pages long, the first 30 pages are in english and the back 30 are in Spanish. Instead of deploying a completely custom web application, I used a new, but existing off the shelf application called pdf.ai which allows you to use genAI to ask questions of your pdf file as well as get clarifications on what it means/says. I also know the founder of this tool and can confirm that they used OpenAI LLMs and set the temperature to 0. Meaning that it should have the lowest probability of chaotically hallucinating and will for the most part not use external data that we do not give it. Additionally this tool will highlight page numbers when it pulls from the external data source and, by using this tool we do not need to go through formatting where a 68 page pdf is too large a file to have as one data source, it would otherwise need to be split into multiple files. The plan is to slice the pdf into different sized chunks and then to ask the different chunks the same questions and see how varied or accurate the answers are. Application to the real worldOne quick note before we dive into the actual experiment, I want to call out how this applies to the real world. I have several clients that have published extensive knowledge bases. Fundamentally a user will visit the knowledge base for answers to their questions but the knowledge base does not always have the best answer, more personalized or accurate answer. We could very easily build a chat interface with genAI to solve this. Think: getting product recommendations from a genAI assistant at Target, understanding niche rules about your 401K from Fidelity or asking a chatbot at Sunrun what typical solar installations cost and look like in your city/zip code. Questions and thoughtsWhat is this document? First question we asked was what is this document? I wanted to see if it was self aware or could find the context of the document in itself. 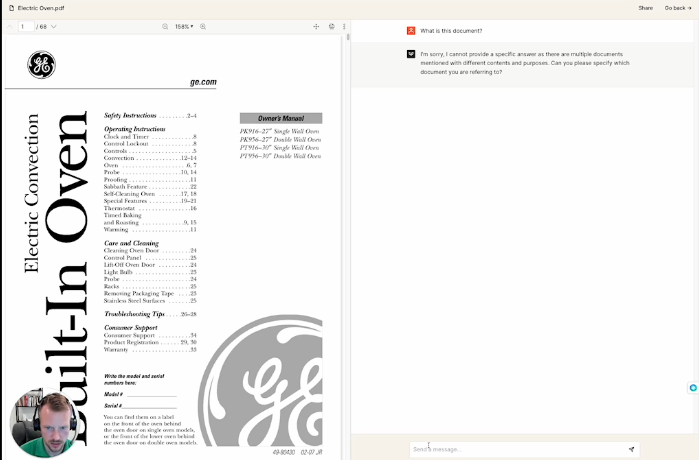  Analysis This blew my mind. Page 1 is in all four files, but somehow between 15-30 pages it’s almost as if there is too much data for the LLM to understand what the document is. I expected this for the full document as the back half was in Spanish, but wow. Is there a child safety measure? It’s an oven, I thought there has to be advice on keeping children safe around it… 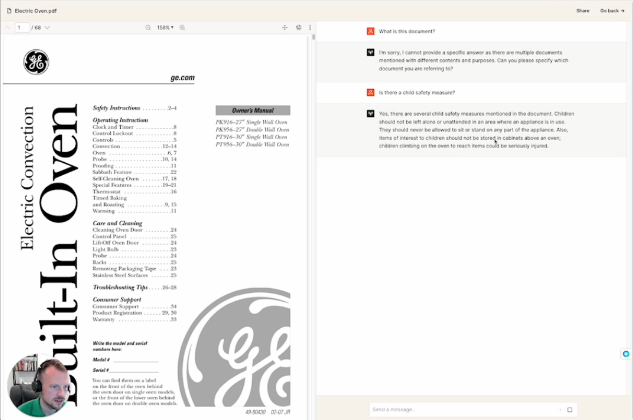  Analysis All four found the same details on page 2 around child safety. Write me a user story for an app that gives appliance instructions to owners. Clearly in this question I am seeing what level of hallucination will be triggered and to see if it can cross the divide from external data to LLM and back. I expected that it would use the data in the document to write a user story, the knowledge to write a user story comes from the LLM. 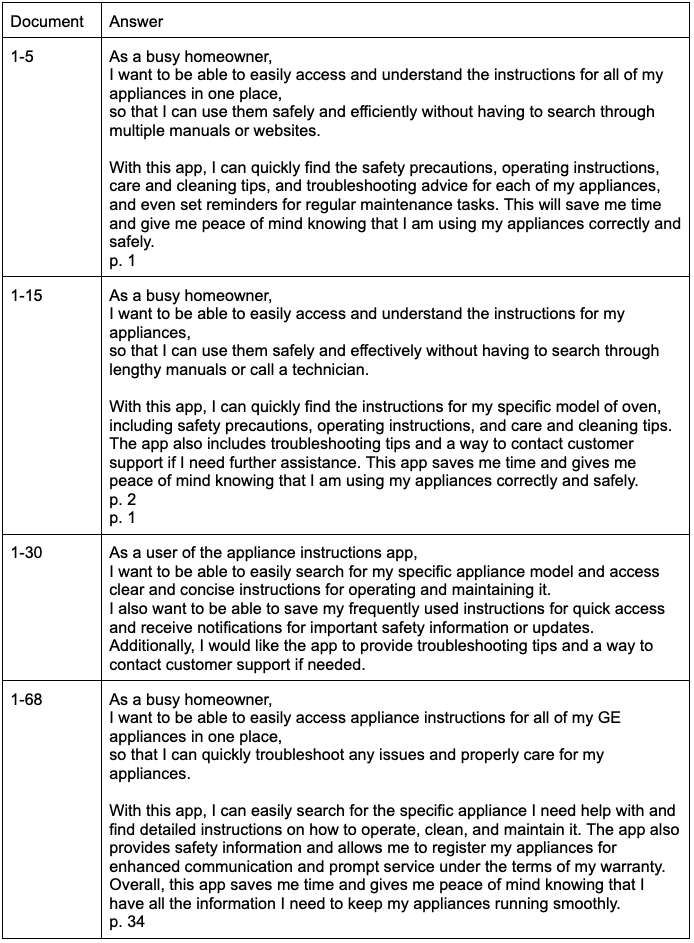 Analysis This was interesting to me as the longest answer was the last and referenced pages not in the other 3 (obviously). Also the 3rd user story missed the “so that” line and there were no acceptance criteria. And, let’s be honest, for a general user story prompt the tool did a fabulous job. If my client wrote these stories I would take no issue with them. Remember, this isn’t a specifically trained PM language model. This is the standard set of OpenAI tools. Also note - the user story on the first five pages of the document looks great. Very little external data needed. Write me a user story for an app that gives appliance instructions to owners using only information from this document. This was an experiment to see how much of the content of user story was actually generated from the information used in the model rather than the document (via deduction) 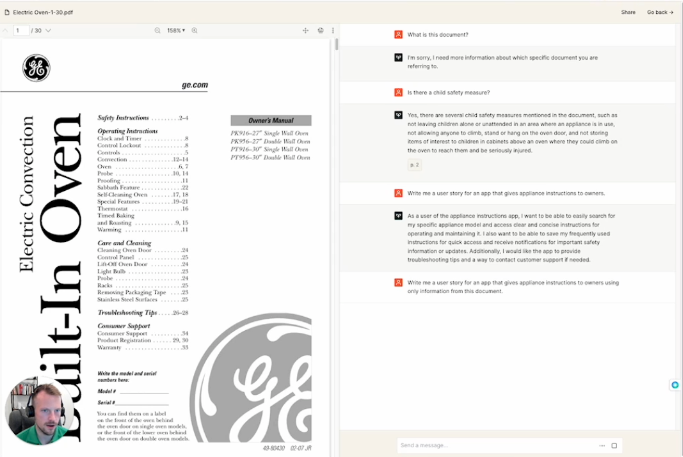   Analysis Again all 4 could write stories, however none could produce a “so that” line. Makes sense, that information would never be in this document. Also notice the first three didn’t deduce that the user was a homeowner anymore and that all 4 stories reference different pages in the document Who was the first president of America? After the reduction in scope of the user story I wanted to test the set up outright on if it could answer a plainly factual question whose data is not in the document.  Analysis It’s cute that they all said no, just in different ways. These answers should give a sigh of relief that we can use this technology in a way where we do not need to worry about hallucination. Secondly - this should trigger further exploration into the answers of this question at different “temperatures” What is the warranty on this appliance? Knowing that the warranty information is on page 33, we asked it a specific question that 3 of the 4 documents should not be able to answer. We would expect given they all have the table of contents they point us to the warranty section  Analysis Fascinating answers. So in the first two it points you to the table of contents. The third one doesn’t but gives you a way to get them through contact details and the fourth one gives you perfect warranty details. My lightbulb has gon out. Is this covered by waranty? Next I wanted to test two things. First a user is more likely to ask about a specific part that needs a warranty check, so lets ask that. And secondly, will it understand me if I purposefully misspell words. Analysis Again 1 and 2 don’t have enough data, 3 points you to the right section and 4 answers the question based on what it knows. I see a meta product action forming here - if a user isn’t getting the answer they want, they’ll be ringing GE to get an answer. This chat interface can ask, does this answer the question? And connect them to support if not. BUT then GE knows which data is lacking and can add it to the knowledgebase so that they can reduce support costs. What ways can I repurpose this document into an app? I wanted to revisit the question of whether with the help of the LLM, this can identify what this document is about and can suggest turning it into something else. 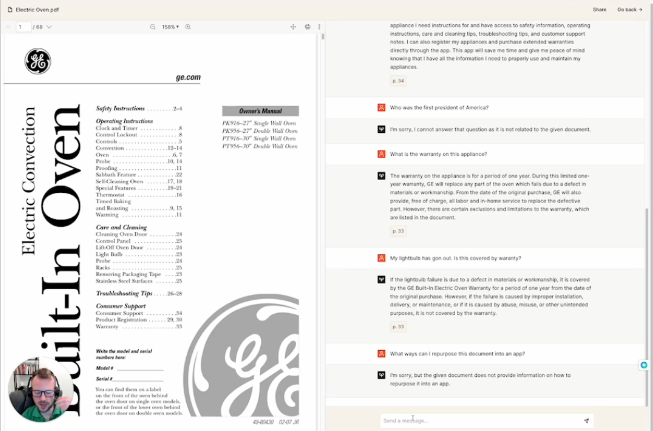  Analysis There’s almost a flash of genius here. Somewhere between 5 and 15 pages there is enough data for the tool to understand what it is and how it can be repurposed as an app, but by range 30-68 there is too much data to successfully pull that off. This is somewhat in line with the answers to the first question in the experiment. The microwave wont start, what should I try? This is an adjacent question. GE makes a microwave in this series but does not mention it in the document so let's see if it can solve this question.  Solid answers. It knows the document is about an oven and does not hallucinate. ConclusionThrough my crude experiment, my general feeling is that a team only needs about 15 pages of external data to make a usable product with an OpenAI language model.
From a brief set of discussions externally, most organizations are under the impression that they will need to invest hundreds of hours and have 1000s of pages of data to create a usable product. This is not the case. Additionally - there is argument to be made for starting small and by way of the answers adding more information as needed to get the right responses.
1 Comment
|
Archives
June 2024
Categories
All
|
 RSS Feed
RSS Feed